A how-to guide: AWS cost and usage reporting from multiple AWS accounts

Editor’s Note: This article originally appeared on the Cloudera Foundation website. In April 2021, the Cloudera Foundation merged with the Patrick J. McGovern Foundation.
by Hazem Mahmoud
March 23, 2020
In our line of work, we focus on enabling nonprofit organizations to use the power of data and analytics to help them advance their goals. We deeply believe that the use of data and data technologies can bring about positive impact in our world.
We recently launched an Accelerator program that allows NGOs to test out hypotheses they may have in the work they do. This program provides a data platform (donated by Cloudera, Inc.), where the organizations can bring in their datasets, run queries and analytics on their data, and find potential data insights and signals that they may not have been able to identify previously. This is coupled with technical expertise/guidance and training by Cloudera and Cloudera Foundation staff, along with a financial grant from the Foundation.
Cloudera Foundation restricted a certain amount of funding for cloud compute and storage costs. We initially attempted to estimate the cloud costs based on projected grantee workloads, but realized we needed our estimates to be backed by data in order to improve future cost estimates. The below tool was developed in an effort to ensure that the grantees stay within those costs, and to gain visibility into the variability in patterns of usage as the projects get under way.
AWS provides a Cost & Usage Reporting (CUR) feature that allows AWS accounts to generate cost and usage data, to be used for analytics and forecasting purposes. The data is sent to S3, and queryable using Athena, Redshift or QuickSight. The Accelerator program requires the grantees bring their own AWS accounts, to ensure proper isolation between each of the grantee projects. However, such isolation made it difficult to utilize the AWS tools (Athena/Redshift/QuickSight) and hence we decided to pull the CUR files from each AWS account to perform our own analytics and reporting. Each grantee provided the Foundation with the appropriate permissions to get direct access to the S3 buckets hosting the CUR (CSV) data files. This blog describes the steps needed to develop and deploy this.
I wanted to share this work, because we must not allow the difficulty of managing cloud costs keep nonprofits from boldly experimenting with data-driven solutions. I invite anyone reading this to work with us to innovate together on this issue.
Setting Up AWS CUR
The first step needed was for each of our grantees to set up the AWS CUR in their respective AWS accounts. AWS provides fairly good documentation around how to set up CUR. For our use case, we specified a few options to make this work for our needs. Here are the steps our grantees took on their AWS account:
Steps
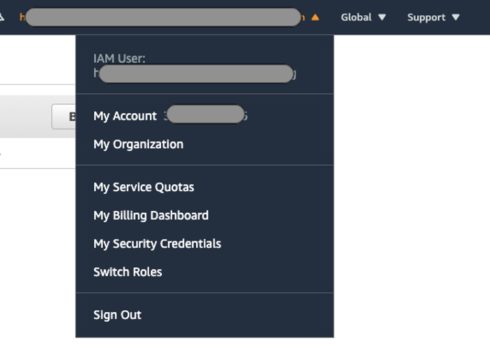
1. Log in to your AWS Account and click on your username on the top right corner of the AWS Console, and click on “My Billing Dashboard”!
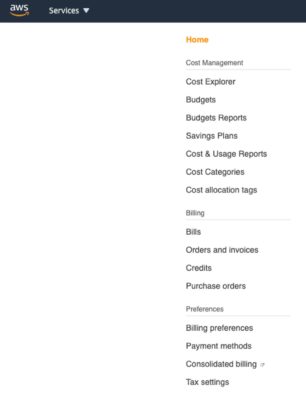
2. Click on the “Cost & Usage Reports” link on left panel, then click the “Create report” button!
3. Provide “Report name” and click Next (leave “Include resource IDs” unchecked)
4. Provide a new S3 bucket that these data sources will be saved by clicking on the S3 bucket “Configure” button!
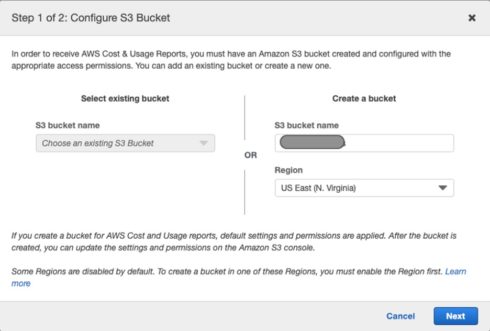
5. Provide a new bucket name (recommendation: <org_name>awscostreports) as well as the region you want this S3 bucket to reside in, and click Next
6. Check the box to verify the policy that will be applied to your new bucket and click Save!
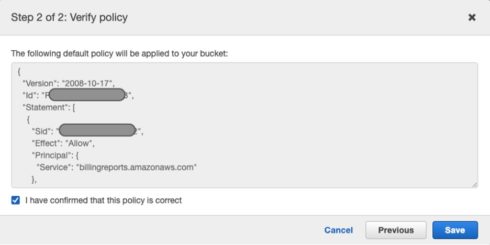
7. This will take you back to the Create report screen where you can set the following:
a. Report path prefix: (recommendation: <org_name>).
b. Time granularity: Daily
c. Report versioning: Create new report version
d. Enable report data integration for: (do not select any of those options)
e. Compression type: GZIP. Click Next
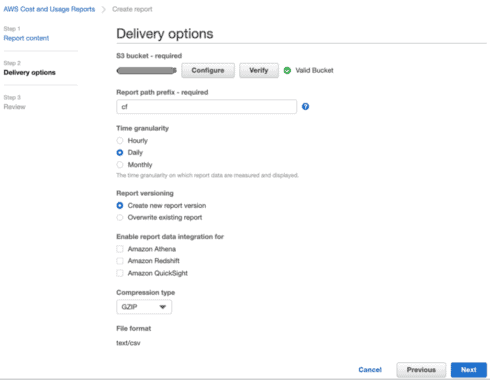
8. In the Review page, review all the details and click “Review and Complete”
9. Next, we need to configure the newly created S3 bucket with the appropriate policy to allow us (the Cloudera Foundation) to pull the cost and usage dataset. To do so, each of our grantees went to AWS → S3 → selected the new bucket created above when creating the Cost and Usage Report.
10. Click on the Permissions tab and in the Bucket Policy section, add the following to allow Cloudera Foundation **read-only** access to **only** this bucket:
{“Sid”: “CF permissions”, “Effect”: “Allow”, “Principal”: { “AWS”: “arn:aws:iam::<aws_acct_id_for_pulling_files>:root” }, “Action”: [ “s3:GetObject”, “s3:ListBucket”], “Resource”: [ “arn:aws:s3:::<grantee_bucket_name>”, “arn:aws:s3:::<grantee_bucket_name>/*” ] }
Note: We will want to add that to the bottom of the existing policy that was already there (auto created by the AWS CUR). Don’t forget to add a “,” after the } for the previous statement.
11. After the bucket policy is modified, we will want to update the Bucket ownership section below the bucket policy:

Click on “Edit”
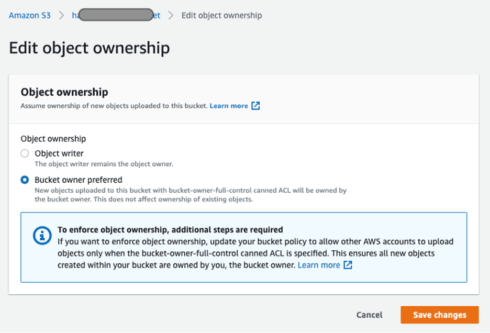
Then select “Bucket owner preferred” and click “Save changes”. This allows any new objects written to this bucket policy to be owned by the AWS account (your account) and not by the “billingreports.amazonaws.com” service. If it’s owned by that service, then the Foundation won’t be able to download those objects (the CSV files).
S3 Bucket Permissions Explanation
As mentioned above, the permissions of the S3 bucket require some additional configurations. This is primarily due to the fact that the bucket objects are being written to by another owner (other than the AWS account that the bucket actually resides in) – the owner being the object writer of billingreports.amazonaws.com. Therefore, we need to change the configuration (Object ownership) so when objects are written to the S3 bucket, they are done so by the “Bucket owner” and not the “Object writer”.
If we don’t do this, trying to pull any of the AWS CUR CSV files using the following command:
aws s3 cp s3://<cur_bucket>/<prefix>/<date_range>/<id>/<gz_csv>
would produce the following error:
fatal error: An error occurred (403) when calling the HeadObject operation: Forbidden
Again, this is the screen we need to update to resolve this error.
AWS CUR Analysis
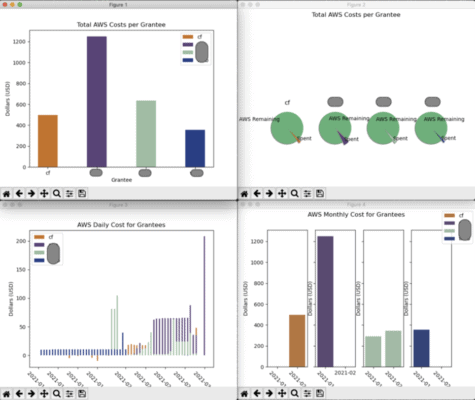
After setting up CUR on each of the respective grantee AWS accounts, we now have access to pull the CSV files and perform our analytics and reporting. The analytics tool we developed in-house for CUR can be found here. It’s basic stuff for now, but we plan to add more features and visualizations to help us keep the AWS costs under control and to provide for better cost projections for future Accelerator grantee projects. The GitHub repository README has more information on configuring and running the tool.
Below is a sample of the visualizations produced by this tool for each of the grantees.
Resources
Controlling ownership of uploaded objects using S3 Object Ownership
This guide is no longer being updated. For current information and instructions, see the new Amazon S3 User Guide.
Hazem is the Data Solutions Architect at the Patrick J. McGovern Foundation.